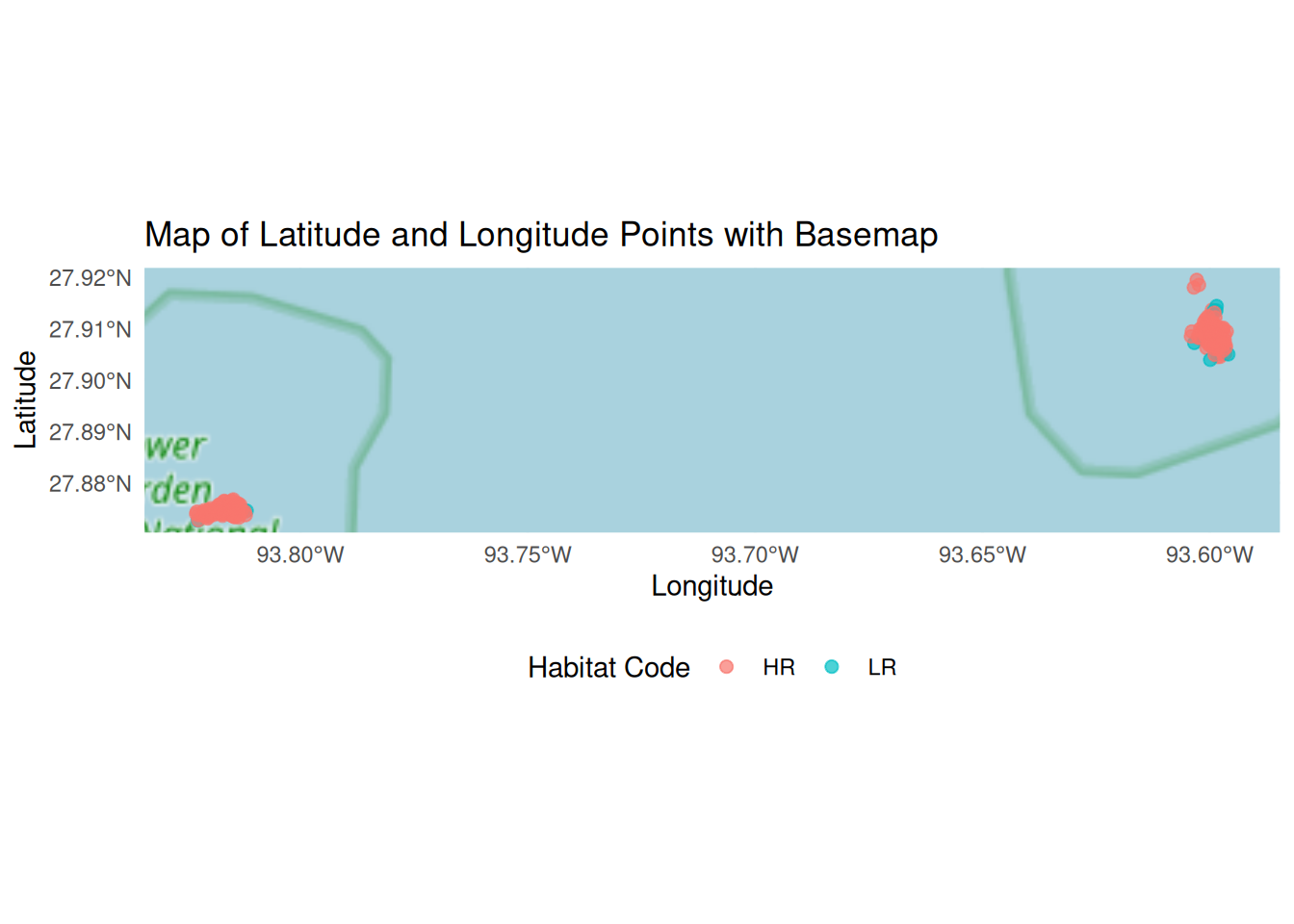
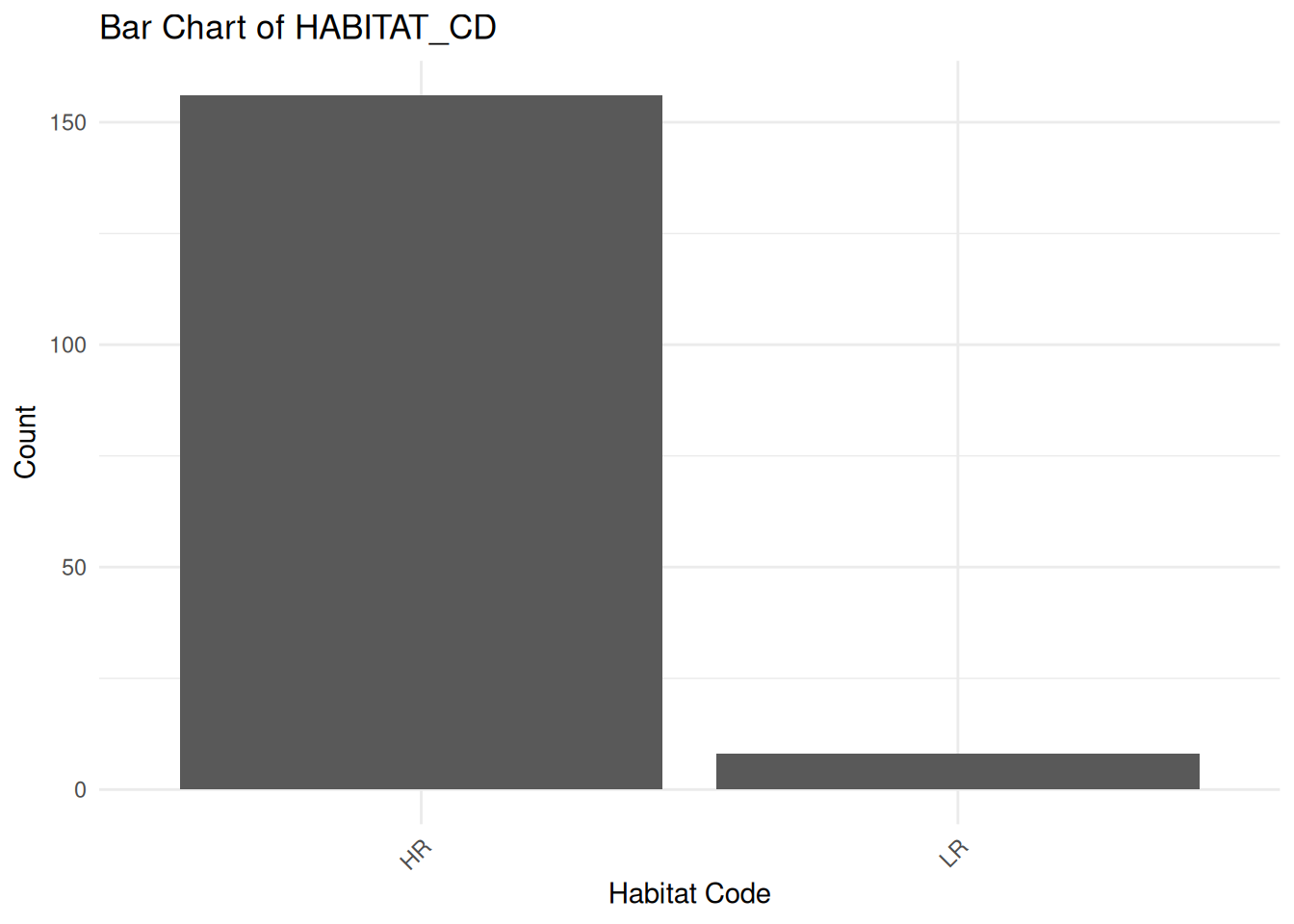
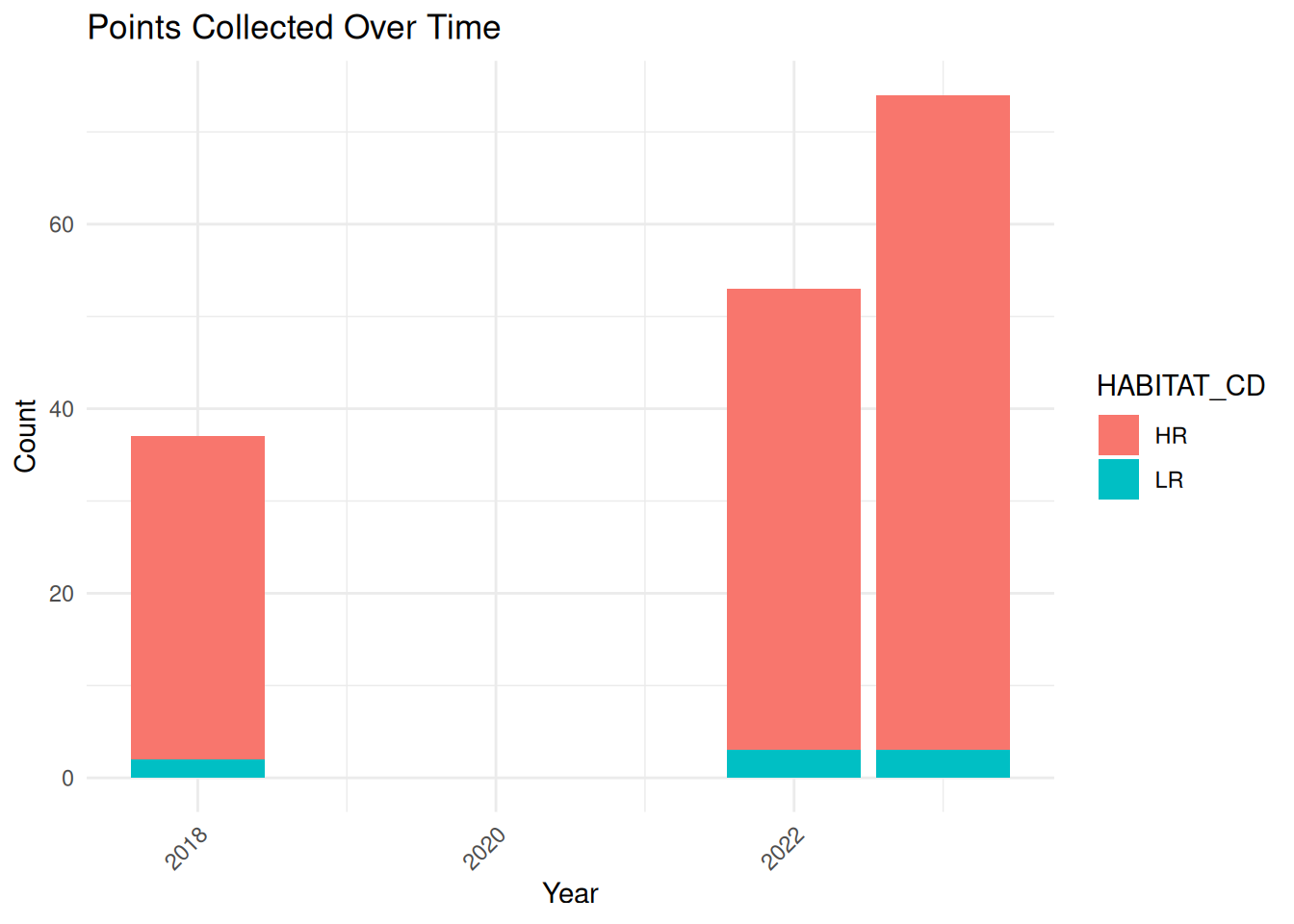
pattern <- paste0({params$inputFilePrefix}, "\\d{4}\\.csv")
# List all files matching the pattern
files <- list.files(
path = here("data/01_raw"), pattern = pattern, full.names = TRUE
)
# Initialize an empty list to store data
data_list <- list()
# Loop over the files
for (file in files) {
# Read the CSV file
data <- read.csv(file)
print(glue("reading {file}..."))
# Select the desired columns
selected_data <- data %>%
select(LAT_DEGREES, LON_DEGREES, YEAR, MONTH, DAY, HABITAT_CD) %>%
mutate(date = sprintf("%04d-%02d-%02d", YEAR, MONTH, DAY)) %>%
mutate(`system:time_start` = as.numeric(as.POSIXct(
date, format="%Y-%m-%d", tz="UTC"
)) * 1000) %>%
select( -MONTH, -DAY) %>%
rename(latitude = LAT_DEGREES, longitude = LON_DEGREES)
# Keep only the rows with unique values across the selected columns
unique_data <- selected_data %>%
distinct()
# Append the data to the list
data_list[[length(data_list) + 1]] <- unique_data
}