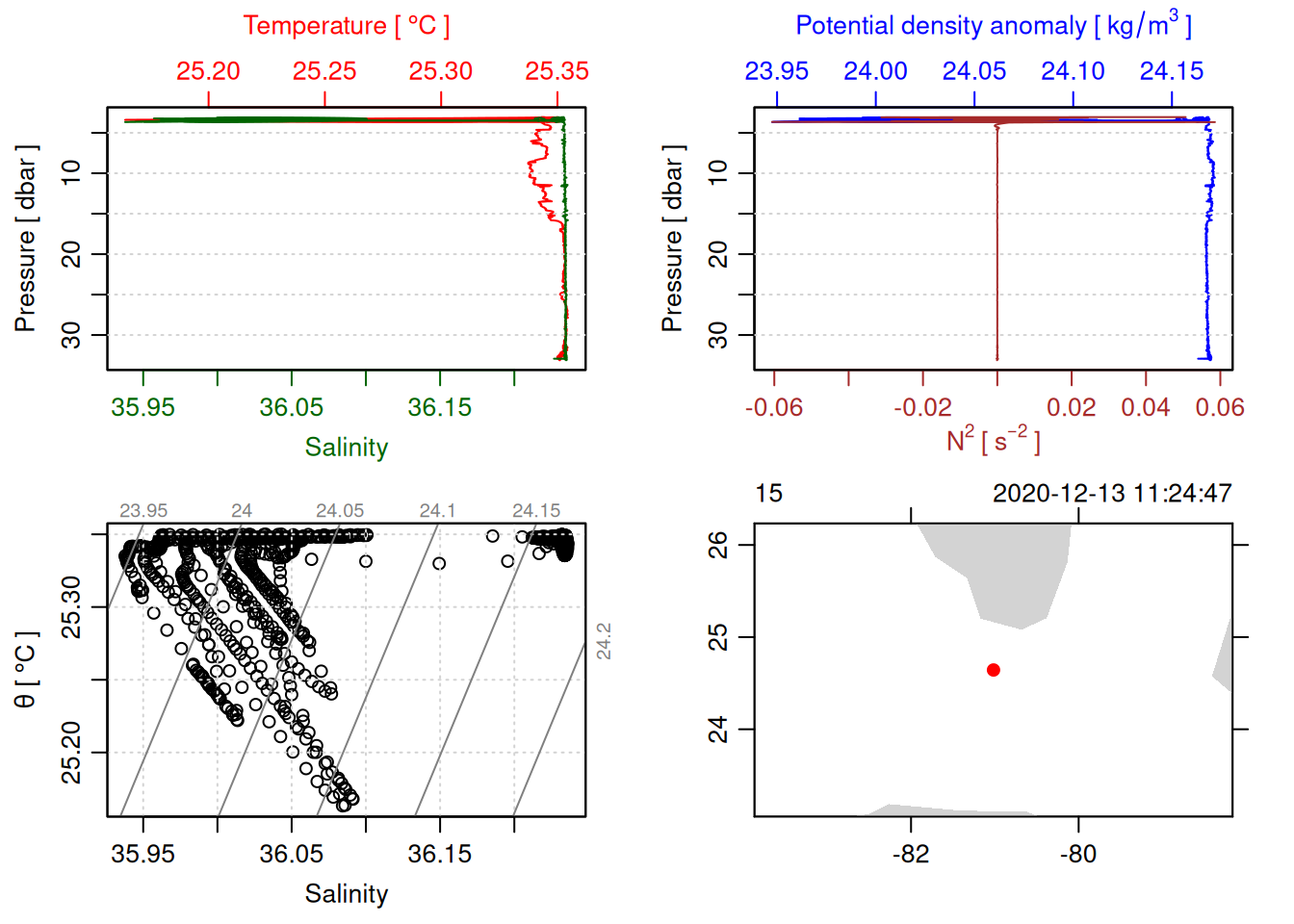
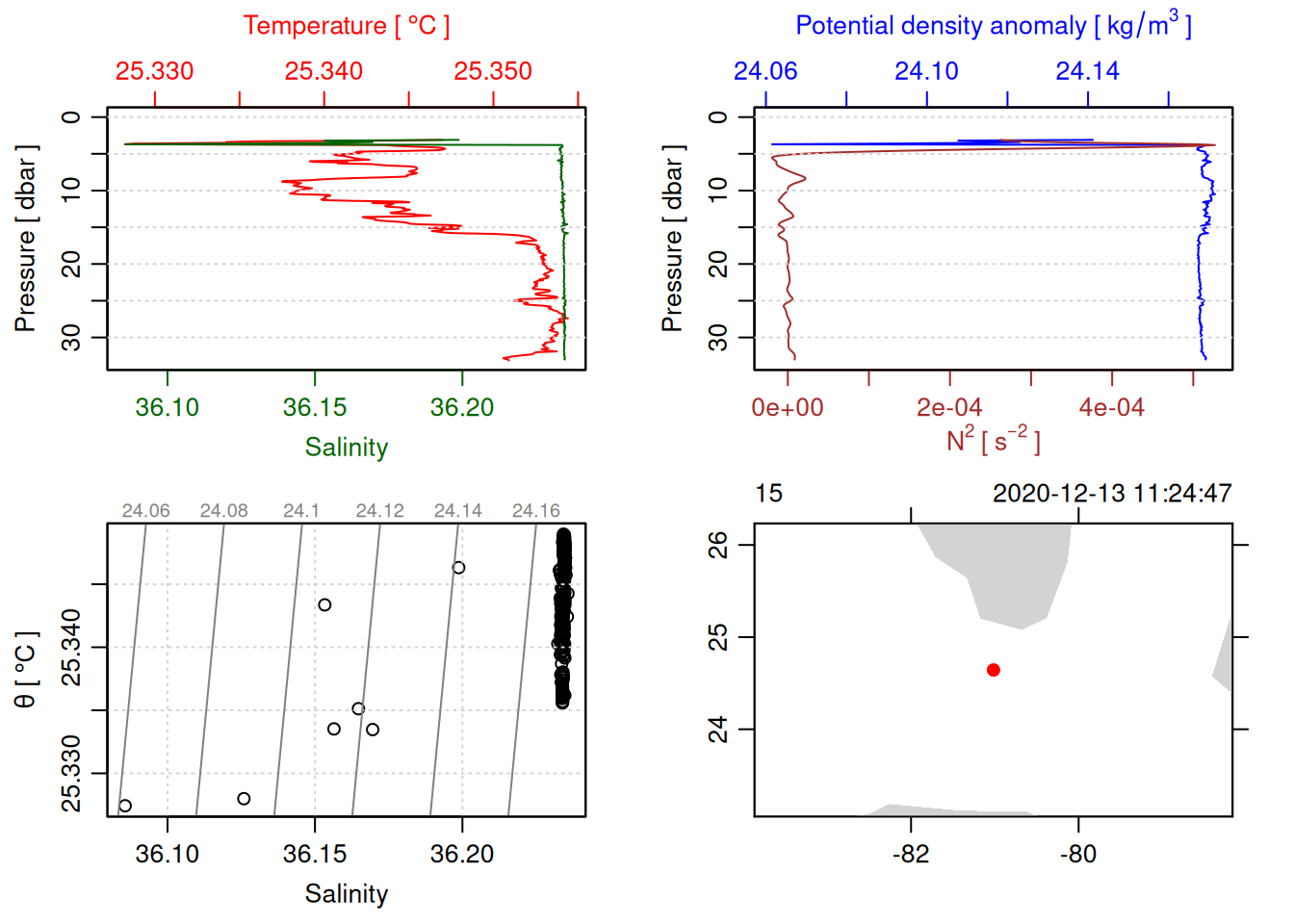
WS20342_WS20342_WS20342_15.csv
Added 56 additional parameters to CTD object
create an oce CTD object
# TODO: Include param here that specifies to handle QC flags. This should be done before converting to a OCE object. QC flag columns are listed in [this spreadsheet](https://docs.google.com/spreadsheets/d/1uCxEmJRqErU-HCQiRQ1FpyiIqtNaGgMSBI0WvrtwBRU/edit?gid=137286311#gid=137286311) and are not supposed to be included in the oce object. QC param values are : # 1 good# 2 +/- 3*std_dev# 4 +/- 5*std_dev# 9 missing# Data column should be set to NA if corresponding QC column has value greater than threshold (recommended threshold is 5*std_dev).# Will need to loop through *_qc columns.# TODO: drop spikes (how? low-pass?).# TODO: combine replicate sensors (eg temp1 temp2).
tryCatch({ trimmed_cast <-ctdTrim(cast) decimated_cast <-ctdDecimate(trimmed_cast, p =0.1)# plotting can cause the xlim failureplot(decimated_cast)# === export ===# Get the scan numbers that remain after cleaning cleaned_scans <- decimated_cast@data$scan# Load original raw data to keep all columns ctd_raw <- readr::read_csv(dataFile, show_col_types =FALSE)# Filter raw data to only include the cleaned scans cast_df <- ctd_raw %>%filter(!is.na(sea_water_pressure)) %>%# Remove rows without pressure datamutate(row_num =row_number()) %>%filter(row_num %in% cleaned_scans) %>%select(-row_num)# Add metadata cast_df <-mutate( cast_df,station = station_id,cruise_id = cruise_id )# Check if there are any rows in the cleaned dataif (nrow(cast_df) ==0) {cat("\n=== WARNING: NO DATA AFTER CLEANING ===\n")cat("Cast ID:", params$cast_id, "\n")cat("Station:", station_id, "\n")cat("Cruise:", cruise_id, "\n\n")cat("Raw data rows (with pressure):", sum(!is.na(ctd_raw$sea_water_pressure)), "\n")cat("Cleaned scans to keep:", length(cleaned_scans), "\n")cat("Resulting rows:", nrow(cast_df), "\n\n")cat("Raw data summary:\n")print(summary(ctd_raw[c("sea_water_pressure", "sea_water_temperature", "sea_water_salinity")]))cat("\nCleaned scans (first 20):\n")print(head(cleaned_scans, 20))cat("\n=== CSV FILE NOT CREATED (no data) ===\n\n") } else {# create folder if doesn't exist clean_data_loc <- here::here("data/02_clean")try(fs::dir_create(clean_data_loc))# save ctd to .csv (without row names/indices)write.csv(cast_df, glue("{clean_data_loc}/{params$cast_id}.csv"), row.names =FALSE)cat("Successfully saved", nrow(cast_df), "rows to", glue("{params$cast_id}.csv"), "\n") }}, error =function(e) {cat("\n=== CTD PROCESSING ERROR ===\n")cat("Cast ID:", params$cast_id, "\n")cat("Error message:\n", conditionMessage(e), "\n\n")# Safely inspect objects that might or might not exist when the error happenedif (exists("decimated_cast")) { df <-try(as.data.frame(decimated_cast@data), silent =TRUE)if (!inherits(df, "try-error")) {cat("Dataframe columns:\n")print(names(df))cat("\nSummary of key columns (scan, pressure, temperature, salinity if present):\n") known_cols <-intersect(c("scan", "pressure", "temp", "temperature", "salinity", "conductivity"), names(df))print(summary(df[known_cols], digits =3))cat("\nHead of dataframe:\n")print(head(df)) } else {cat("Could not extract dataframe from decimated_cast.\n") } } else {cat("decimated_cast was never created before the error.\n") }cat("\n=== END ERROR DEBUG INFO ===\n\n")})
Successfully saved 141 rows to WS20342_WS20342_WS20342_15.csv
NOTE: The following plots have been disabled.
To avoid an oversized website, the following plots have been disabled using eval:false. GitHub pages’ free hosting limits websites to 2GB in size; including these plots pushes this website over that limit. To view the outputs you can run the following code locally.