load libraries
librarian::shelf(
dplyr,
tidyr,
here,
DT
)The dashboardData.csv file is in “long” format, with “analyte name” as a column. This document transforms the data to “wide” “tidy” format, with “analyte name” on the columns. This is done by pivoting on the analyte name column.
librarian::shelf(
dplyr,
tidyr,
here,
DT
)library("here")
df_long <- read.csv(here("data/exports/dashboardData.csv"))
# Show dimensions of long format data
cat("Long format dimensions:\n")Long format dimensions:cat(" Rows:", nrow(df_long), "\n") Rows: 1277593 cat(" Columns:", ncol(df_long), "\n") Columns: 10 Before pivoting we assess how many collisions will occur.
df_long %>%
group_by(source, site, datetime, sample_depth, analyte) %>%
summarise(n = n(), .groups = "drop") %>%
filter(n > 1)# A tibble: 252,879 × 6
source site datetime sample_depth analyte n
<chr> <chr> <chr> <dbl> <chr> <int>
1 AOML_FBBB 1 1998-01-20 NA Salinity 2
2 AOML_FBBB 1 1998-01-20 NA Water Temperature 2
3 AOML_FBBB 1 1998-03-10 NA Salinity 2
4 AOML_FBBB 1 1998-03-10 NA Water Temperature 2
5 AOML_FBBB 1 1998-06-30 NA Salinity 2
6 AOML_FBBB 1 1998-06-30 NA Water Temperature 2
7 AOML_FBBB 14 1998-01-21 NA Salinity 2
8 AOML_FBBB 14 1998-01-21 NA Water Temperature 2
9 AOML_FBBB 16 1998-12-21 NA Ammonium, Filtered (NH4) 2
10 AOML_FBBB 16 1998-12-21 NA Chlorophyll a, Corrected for P… 2
# ℹ 252,869 more rowsThese rows will collide with n other rows (see column on far right). An example cause of this is samples that were taken at the same time on the same day. Collisions in this pivot are averaged with a mean.
The transformation uses tidyr::pivot_wider() to convert the dataset from long format (where each row is one measurement of one analyte) to wide format (where each row represents all measurements at a specific location and time).
library(dplyr)
library(tidyr)
# Pivot to wide format using the actual column names from dashboardData.csv
# Columns: source, site, datetime, analyte, value, units, latitude, longitude, sample_depth
df_wide <- df_long %>%
pivot_wider(
id_cols = c(source, site, datetime, units, latitude, longitude, sample_depth),
names_from = analyte,
values_from = value,
values_fn = mean # aggregate duplicates by taking mean
)
# Show dimensions of wide format data
cat("Wide format dimensions:\n")Wide format dimensions:cat(" Rows:", nrow(df_wide), "\n") Rows: 405578 cat(" Columns:", ncol(df_wide), "\n") Columns: 27 cat("\nNumber of analyte columns created:", ncol(df_wide) - 7, "\n")
Number of analyte columns created: 20 # Display first 100 rows with scrolling
DT::datatable(
head(df_wide, 100),
options = list(
scrollX = TRUE,
scrollY = "400px",
pageLength = 10
),
caption = "First 100 rows of wide format data (scroll to see all columns)"
)library(skimr)
# Skim the numeric columns (analyte measurements)
numeric_cols <- sapply(df_wide, is.numeric)
if (sum(numeric_cols) > 0) {
cat("Summary of numeric analyte columns:\n\n")
skim(df_wide[, numeric_cols])
} else {
cat("No numeric columns found in wide format data.\n")
}Summary of numeric analyte columns:| Name | df_wide[, numeric_cols] |
| Number of rows | 405578 |
| Number of columns | 23 |
| _______________________ | |
| Column type frequency: | |
| numeric | 23 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| latitude | 198442 | 0.51 | 25.64 | 0.53 | 24.40 | 25.26 | 25.74 | 25.90 | 28.78 | ▃▇▂▁▁ |
| longitude | 198442 | 0.51 | -80.49 | 0.51 | -85.02 | -80.65 | -80.29 | -80.16 | -80.02 | ▁▁▁▁▇ |
| sample_depth | 242117 | 0.40 | 0.42 | 0.22 | 0.00 | 0.10 | 0.50 | 0.50 | 1.00 | ▃▁▇▂▁ |
| Water Temperature | 305554 | 0.25 | 18.03 | 12.22 | 0.00 | 1.60 | 23.85 | 28.16 | 74.65 | ▅▇▂▁▁ |
| Salinity | 308998 | 0.24 | 16.99 | 16.12 | 0.00 | 1.10 | 13.88 | 34.02 | 933.00 | ▇▁▁▁▁ |
| Dissolved Oxygen | 319898 | 0.21 | 4.19 | 10.83 | 0.00 | 1.37 | 4.60 | 6.34 | 2697.44 | ▇▁▁▁▁ |
| Ammonium, Filtered (NH4) | 370775 | 0.09 | 0.53 | 1.99 | 0.00 | 0.01 | 0.02 | 0.24 | 152.50 | ▇▁▁▁▁ |
| Nitrite (NO2) | 358955 | 0.11 | 0.03 | 0.14 | 0.00 | 0.00 | 0.00 | 0.00 | 14.10 | ▇▁▁▁▁ |
| Nitrate (NO3) | 373447 | 0.08 | 0.34 | 3.50 | -0.03 | 0.00 | 0.01 | 0.04 | 216.06 | ▇▁▁▁▁ |
| NO2+3, Filtered | 344304 | 0.15 | 0.26 | 2.62 | 0.00 | 0.00 | 0.01 | 0.06 | 218.00 | ▇▁▁▁▁ |
| Phosphate, Filtered (PO4) | 361373 | 0.11 | 0.17 | 0.30 | 0.00 | 0.00 | 0.01 | 0.11 | 2.63 | ▇▁▁▁▁ |
| Chlorophyll a, Corrected for Pheophytin | 373601 | 0.08 | 2.92 | 7.79 | 0.00 | 0.37 | 0.80 | 2.42 | 747.00 | ▇▁▁▁▁ |
| pH | 333149 | 0.18 | 3.77 | 4.74 | 0.00 | 1.00 | 1.60 | 7.59 | 820.00 | ▇▁▁▁▁ |
| Specific Conductivity | 402859 | 0.01 | 2600.53 | 9322.27 | 0.00 | 45.30 | 49.56 | 54.89 | 53465.00 | ▇▁▁▁▁ |
| Turbidity | 329066 | 0.19 | 2.35 | 5.21 | 0.00 | 0.50 | 1.00 | 2.35 | 254.00 | ▇▁▁▁▁ |
| Total Kjeldahl Nitrogen | 374234 | 0.08 | 0.52 | 0.47 | 0.00 | 0.10 | 0.44 | 0.81 | 9.20 | ▇▁▁▁▁ |
| Total Phosphorus | 354804 | 0.13 | 0.03 | 0.08 | 0.00 | 0.01 | 0.01 | 0.03 | 3.38 | ▇▁▁▁▁ |
| Total Nitrogen | 373466 | 0.08 | 0.69 | 3.90 | 0.00 | 0.20 | 0.34 | 0.55 | 296.21 | ▇▁▁▁▁ |
| Nitrogen, organic | 381248 | 0.06 | 0.73 | 4.16 | 0.00 | 0.21 | 0.33 | 0.54 | 292.07 | ▇▁▁▁▁ |
| Chlorophyll a, Uncorrected for Pheophytin | 377366 | 0.07 | 2.24 | 2.90 | 0.01 | 0.38 | 1.13 | 3.02 | 55.12 | ▇▁▁▁▁ |
| Dissolved Oxygen Saturation | 405090 | 0.00 | 93.37 | 16.77 | 36.23 | 84.46 | 94.53 | 100.72 | 147.89 | ▁▂▇▂▁ |
| Total Suspended Solids | 401278 | 0.01 | 4.46 | 6.88 | 0.02 | 1.10 | 2.03 | 4.40 | 83.00 | ▇▁▁▁▁ |
| Ammonia, Un-ionized (NH3) | 388210 | 0.04 | 0.79 | 0.33 | 0.00 | 0.50 | 1.00 | 1.00 | 1.00 | ▂▁▂▁▇ |
To make analysis easier, an unique ID is given to each row to identify the spatial location. This identifier can be built from {source}-{site}-{depth}.
df_wide$site_id <- paste(
df_wide$source,
df_wide$site,
ifelse(is.na(df_wide$sample_depth), "NA", df_wide$sample_depth),
sep = "-"
)
# Display first 100 rows with scrolling
DT::datatable(
head(df_wide, 100),
options = list(
scrollX = TRUE,
scrollY = "400px",
pageLength = 10
),
caption = "Wide format data with site_id column (scroll to see all columns)"
)# desired remaining columns: analytes, datetime, site_id, depth
# Get analyte column names (all columns except the id columns)
id_columns <- c("source", "site", "units", "latitude", "longitude", "sample_depth", "site_id", "datetime")
analyte_columns <- setdiff(names(df_wide), id_columns)
# Keep only datetime, site_id, sample_depth, and all analyte columns
df_wide <- df_wide %>%
select(site_id, datetime, sample_depth, all_of(analyte_columns))
# Display first 100 rows with scrolling
DT::datatable(
head(df_wide, 100),
options = list(
scrollX = TRUE,
scrollY = "400px",
pageLength = 10
),
caption = "Cleaned wide format data with selected columns (scroll to see all columns)"
)id_columns <- c("source", "site", "units", "latitude", "longitude", "sample_depth", "site_id", "datetime")
analyte_columns <- setdiff(names(df_wide), id_columns)
library(dplyr)
library(tidyr)
library(knitr)
df_wide %>%
summarise(across(all_of(analyte_columns), ~ sum(!is.na(.)))) %>%
pivot_longer(
cols = everything(),
names_to = "Analyte",
values_to = "Valid_Count"
) %>%
kable(caption = "Number of Valid Values per Analyte")| Analyte | Valid_Count |
|---|---|
| Water Temperature | 100024 |
| Salinity | 96580 |
| Dissolved Oxygen | 85680 |
| Ammonium, Filtered (NH4) | 34803 |
| Nitrite (NO2) | 46623 |
| Nitrate (NO3) | 32131 |
| NO2+3, Filtered | 61274 |
| Phosphate, Filtered (PO4) | 44205 |
| Chlorophyll a, Corrected for Pheophytin | 31977 |
| pH | 72429 |
| Specific Conductivity | 2719 |
| Turbidity | 76512 |
| Total Kjeldahl Nitrogen | 31344 |
| Total Phosphorus | 50774 |
| Total Nitrogen | 32112 |
| Nitrogen, organic | 24330 |
| Chlorophyll a, Uncorrected for Pheophytin | 28212 |
| Dissolved Oxygen Saturation | 488 |
| Total Suspended Solids | 4300 |
| Ammonia, Un-ionized (NH3) | 17368 |
library(skimr)
# Skim the numeric columns (analyte measurements)
numeric_cols <- sapply(df_wide, is.numeric)
if (sum(numeric_cols) > 0) {
cat("Summary of numeric analyte columns:\n\n")
skim(df_wide[, numeric_cols])
} else {
cat("No numeric columns found in wide format data.\n")
}Summary of numeric analyte columns:| Name | df_wide[, numeric_cols] |
| Number of rows | 405578 |
| Number of columns | 21 |
| _______________________ | |
| Column type frequency: | |
| numeric | 21 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| sample_depth | 242117 | 0.40 | 0.42 | 0.22 | 0.00 | 0.10 | 0.50 | 0.50 | 1.00 | ▃▁▇▂▁ |
| Water Temperature | 305554 | 0.25 | 18.03 | 12.22 | 0.00 | 1.60 | 23.85 | 28.16 | 74.65 | ▅▇▂▁▁ |
| Salinity | 308998 | 0.24 | 16.99 | 16.12 | 0.00 | 1.10 | 13.88 | 34.02 | 933.00 | ▇▁▁▁▁ |
| Dissolved Oxygen | 319898 | 0.21 | 4.19 | 10.83 | 0.00 | 1.37 | 4.60 | 6.34 | 2697.44 | ▇▁▁▁▁ |
| Ammonium, Filtered (NH4) | 370775 | 0.09 | 0.53 | 1.99 | 0.00 | 0.01 | 0.02 | 0.24 | 152.50 | ▇▁▁▁▁ |
| Nitrite (NO2) | 358955 | 0.11 | 0.03 | 0.14 | 0.00 | 0.00 | 0.00 | 0.00 | 14.10 | ▇▁▁▁▁ |
| Nitrate (NO3) | 373447 | 0.08 | 0.34 | 3.50 | -0.03 | 0.00 | 0.01 | 0.04 | 216.06 | ▇▁▁▁▁ |
| NO2+3, Filtered | 344304 | 0.15 | 0.26 | 2.62 | 0.00 | 0.00 | 0.01 | 0.06 | 218.00 | ▇▁▁▁▁ |
| Phosphate, Filtered (PO4) | 361373 | 0.11 | 0.17 | 0.30 | 0.00 | 0.00 | 0.01 | 0.11 | 2.63 | ▇▁▁▁▁ |
| Chlorophyll a, Corrected for Pheophytin | 373601 | 0.08 | 2.92 | 7.79 | 0.00 | 0.37 | 0.80 | 2.42 | 747.00 | ▇▁▁▁▁ |
| pH | 333149 | 0.18 | 3.77 | 4.74 | 0.00 | 1.00 | 1.60 | 7.59 | 820.00 | ▇▁▁▁▁ |
| Specific Conductivity | 402859 | 0.01 | 2600.53 | 9322.27 | 0.00 | 45.30 | 49.56 | 54.89 | 53465.00 | ▇▁▁▁▁ |
| Turbidity | 329066 | 0.19 | 2.35 | 5.21 | 0.00 | 0.50 | 1.00 | 2.35 | 254.00 | ▇▁▁▁▁ |
| Total Kjeldahl Nitrogen | 374234 | 0.08 | 0.52 | 0.47 | 0.00 | 0.10 | 0.44 | 0.81 | 9.20 | ▇▁▁▁▁ |
| Total Phosphorus | 354804 | 0.13 | 0.03 | 0.08 | 0.00 | 0.01 | 0.01 | 0.03 | 3.38 | ▇▁▁▁▁ |
| Total Nitrogen | 373466 | 0.08 | 0.69 | 3.90 | 0.00 | 0.20 | 0.34 | 0.55 | 296.21 | ▇▁▁▁▁ |
| Nitrogen, organic | 381248 | 0.06 | 0.73 | 4.16 | 0.00 | 0.21 | 0.33 | 0.54 | 292.07 | ▇▁▁▁▁ |
| Chlorophyll a, Uncorrected for Pheophytin | 377366 | 0.07 | 2.24 | 2.90 | 0.01 | 0.38 | 1.13 | 3.02 | 55.12 | ▇▁▁▁▁ |
| Dissolved Oxygen Saturation | 405090 | 0.00 | 93.37 | 16.77 | 36.23 | 84.46 | 94.53 | 100.72 | 147.89 | ▁▂▇▂▁ |
| Total Suspended Solids | 401278 | 0.01 | 4.46 | 6.88 | 0.02 | 1.10 | 2.03 | 4.40 | 83.00 | ▇▁▁▁▁ |
| Ammonia, Un-ionized (NH3) | 388210 | 0.04 | 0.79 | 0.33 | 0.00 | 0.50 | 1.00 | 1.00 | 1.00 | ▂▁▂▁▇ |
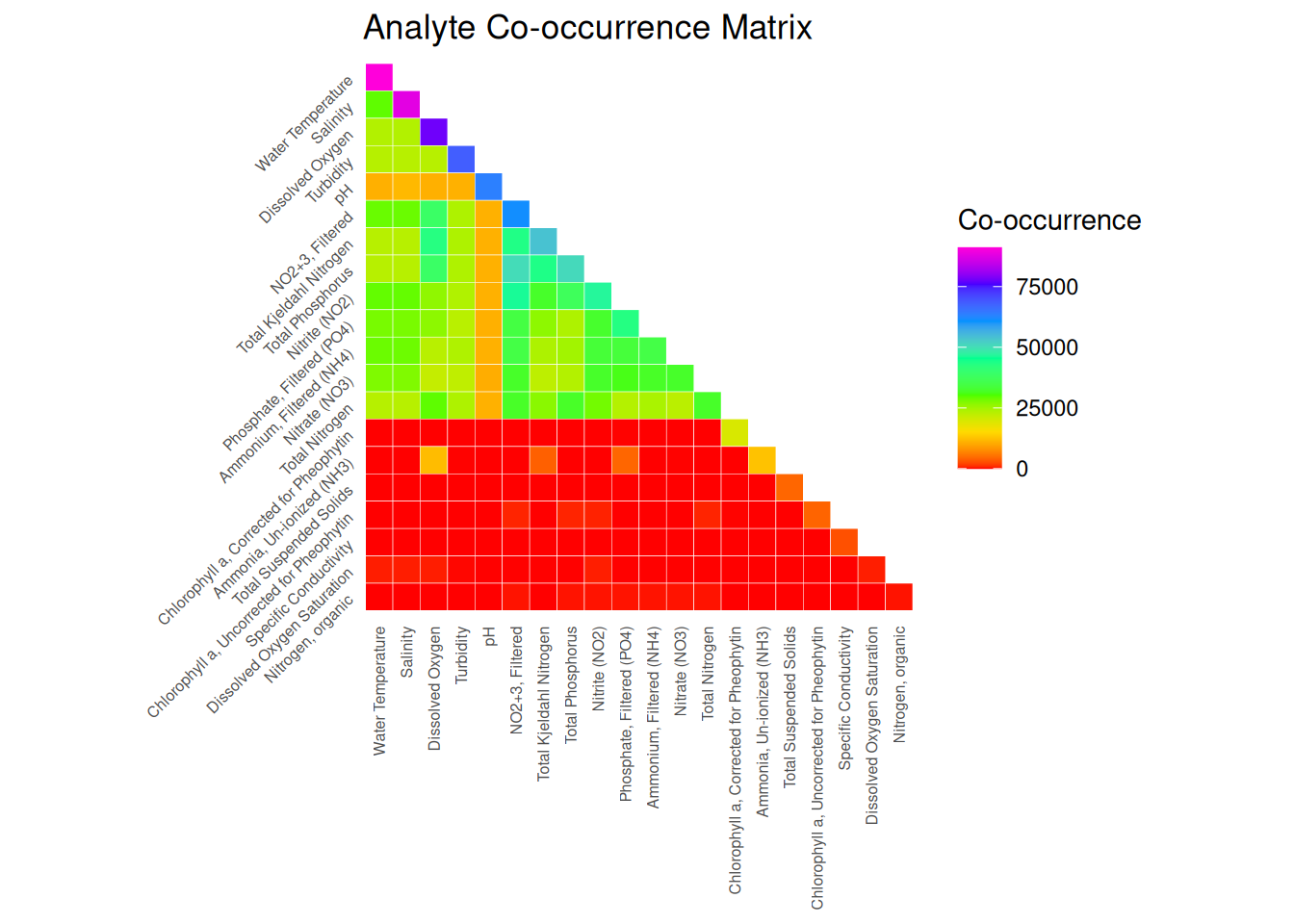
library(dplyr)
library(tidyr)
library(ggplot2)
# 1. compute analyte order (most -> least)
analyte_order <- df_wide %>%
summarise(across(all_of(analyte_columns), ~ sum(!is.na(.)))) %>%
pivot_longer(everything(), names_to = "Analyte", values_to = "Count") %>%
arrange(desc(Count)) %>%
pull(Analyte)
# 2. presence matrix using sorted analytes
presence <- df_wide %>%
mutate(across(all_of(analyte_order),
~ !is.na(suppressWarnings(as.numeric(.))))) %>%
select(all_of(analyte_order))
# 3. co-occurrence matrix (rows/cols are in analyte_order)
cooccurrence_matrix <- t(presence) %*% as.matrix(presence)
# 4. tidy it and set factor levels explicitly
cooccurrence_df <- as.data.frame(cooccurrence_matrix) %>%
mutate(Analyte1 = row.names(.)) %>%
pivot_longer(-Analyte1,
names_to = "Analyte2",
values_to = "Cooccurrence") %>%
mutate(
Analyte1 = factor(Analyte1, levels = analyte_order),
Analyte2 = factor(Analyte2, levels = analyte_order)
) %>%
# Keep only the lower triangle (row >= column)
filter(as.numeric(Analyte1) <= as.numeric(Analyte2))
# 5. plot with y-axis reversed
ggplot(cooccurrence_df, aes(x = Analyte1, y = Analyte2, fill = Cooccurrence)) +
geom_tile(color = "white") +
scale_fill_gradientn(colors = rainbow(7)) +
scale_y_discrete(limits = rev(levels(cooccurrence_df$Analyte2))) + # <-- reverse y-axis
labs(
title = "Analyte Co-occurrence Matrix",
x = NULL,
y = NULL,
fill = "Co-occurrence"
) +
coord_fixed() +
theme_minimal() +
theme(
axis.text.x = element_text(angle = 90, size = 6, vjust = 0.5, hjust = 1),
axis.text.y = element_text(angle = 45, size = 6, hjust = 1),
panel.grid = element_blank()
)
# Export the wide format data
write.csv(df_wide, here("data", "exports", "dashboardData_wide.csv"), row.names = FALSE)
cat("Wide format data exported to: data/exports/dashboardData_wide.csv\n")Note: Ideas for next steps: - Multivariate analysis where you need multiple parameters as separate variables - Creating correlation matrices between different analytes - Machine learning tasks that expect features as columns - Quick comparison of multiple parameters at the same observation point