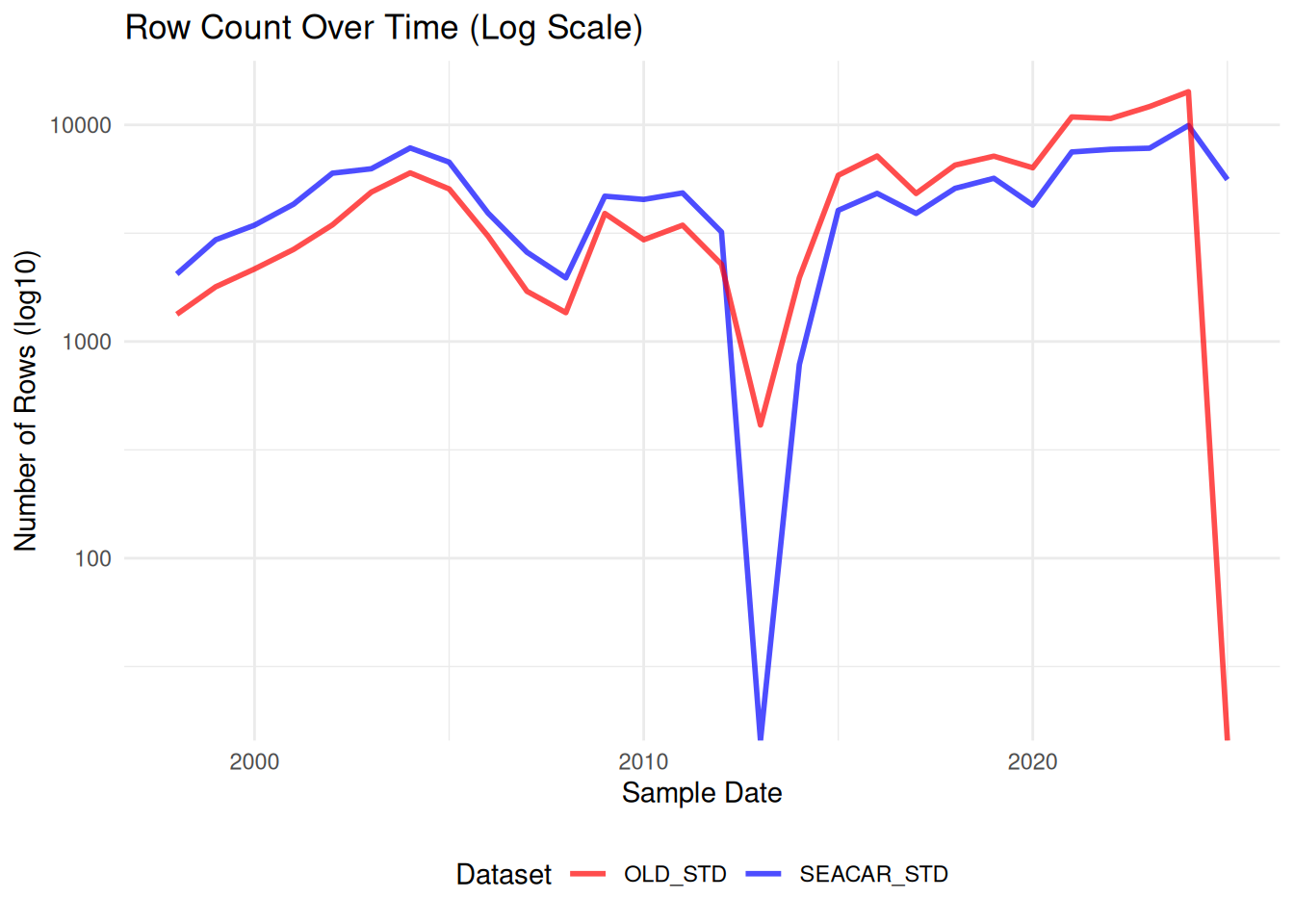
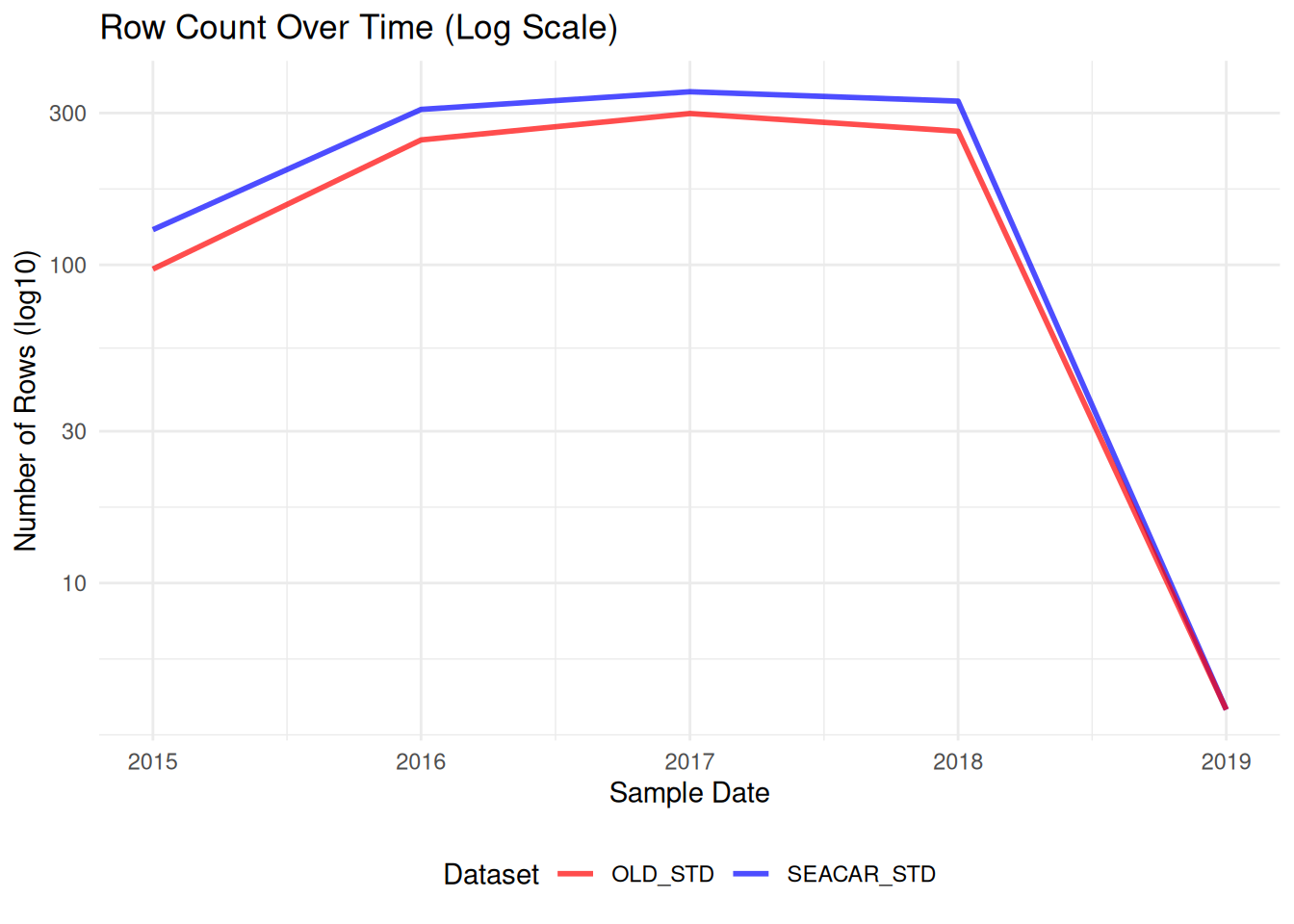
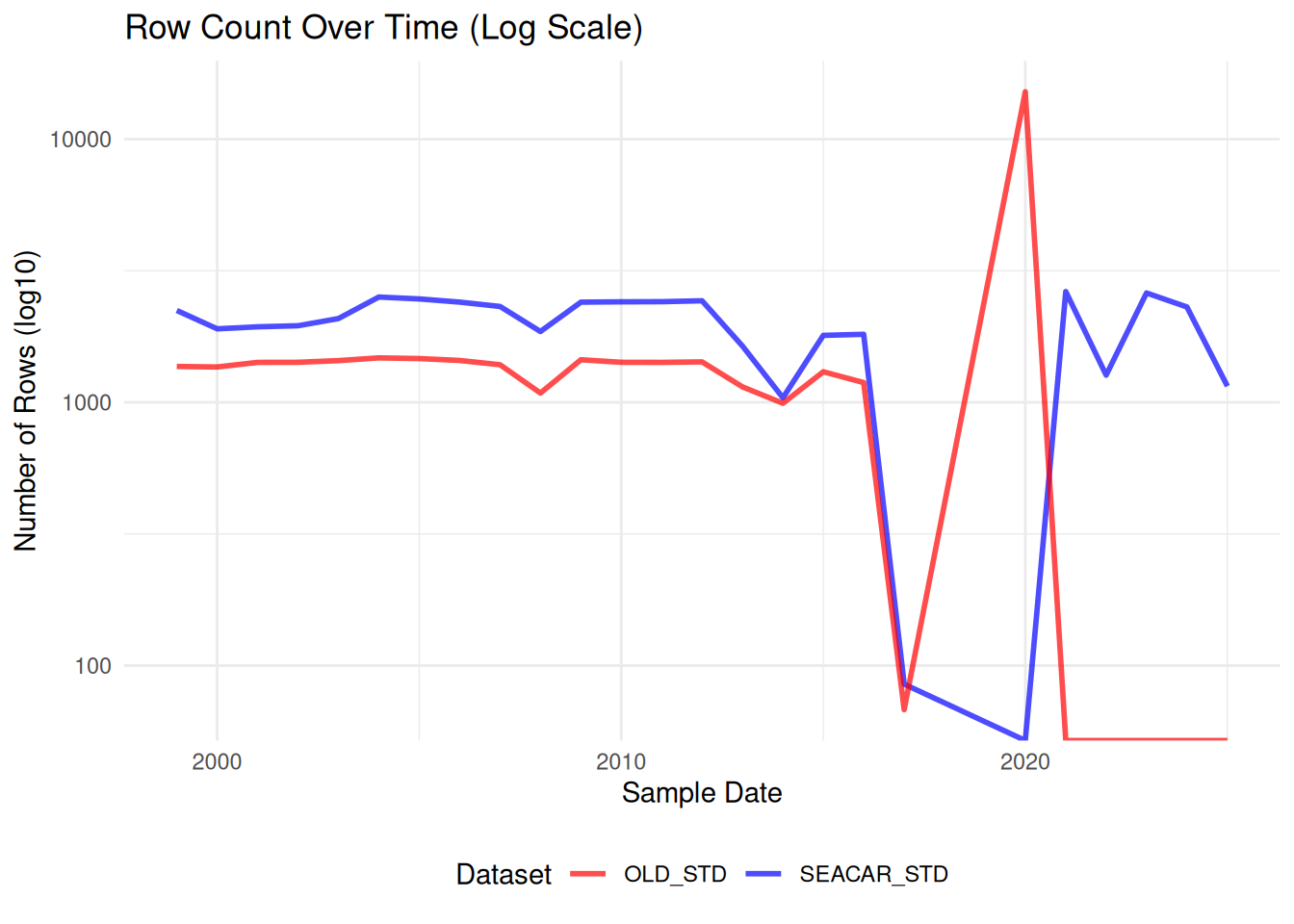
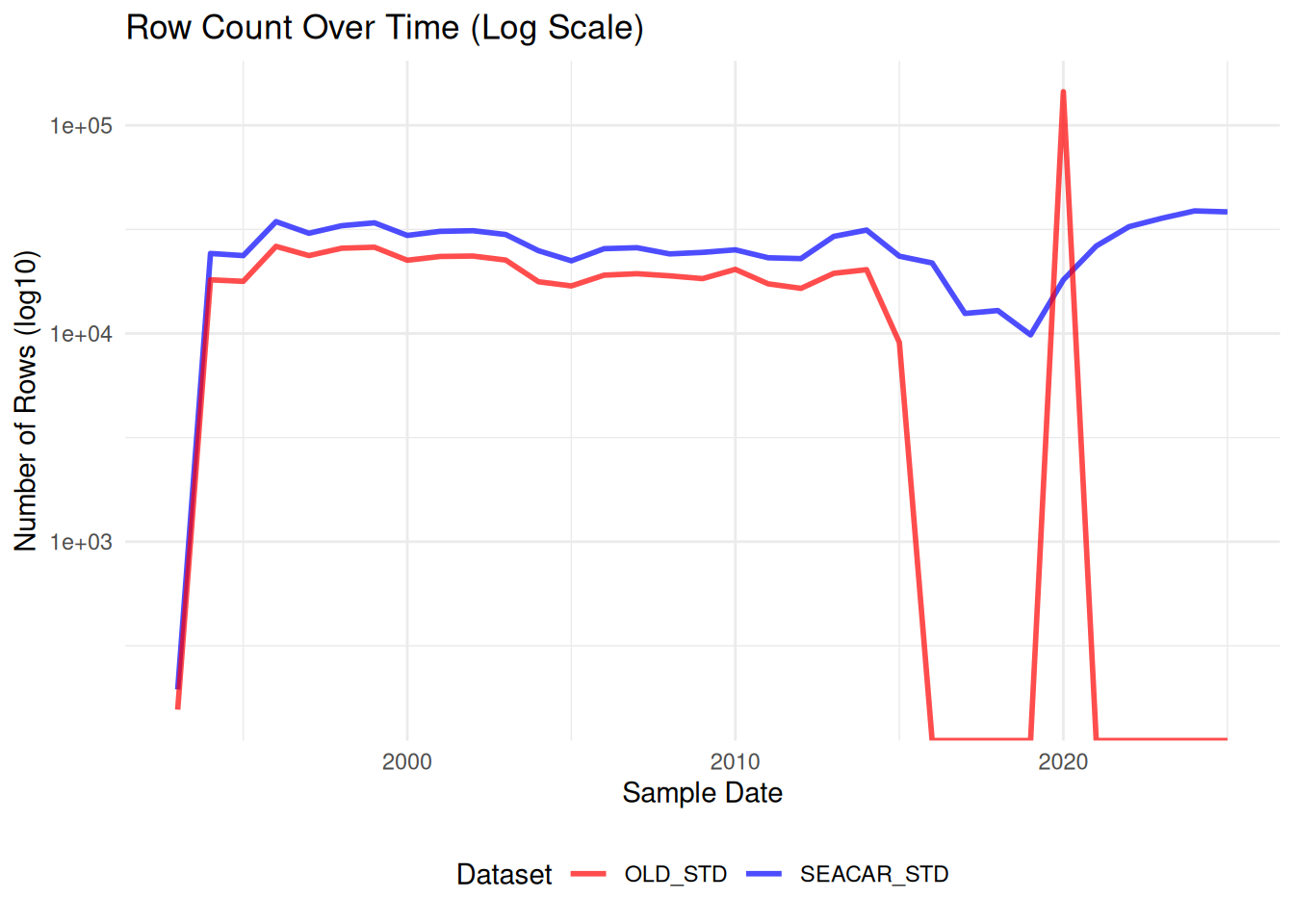
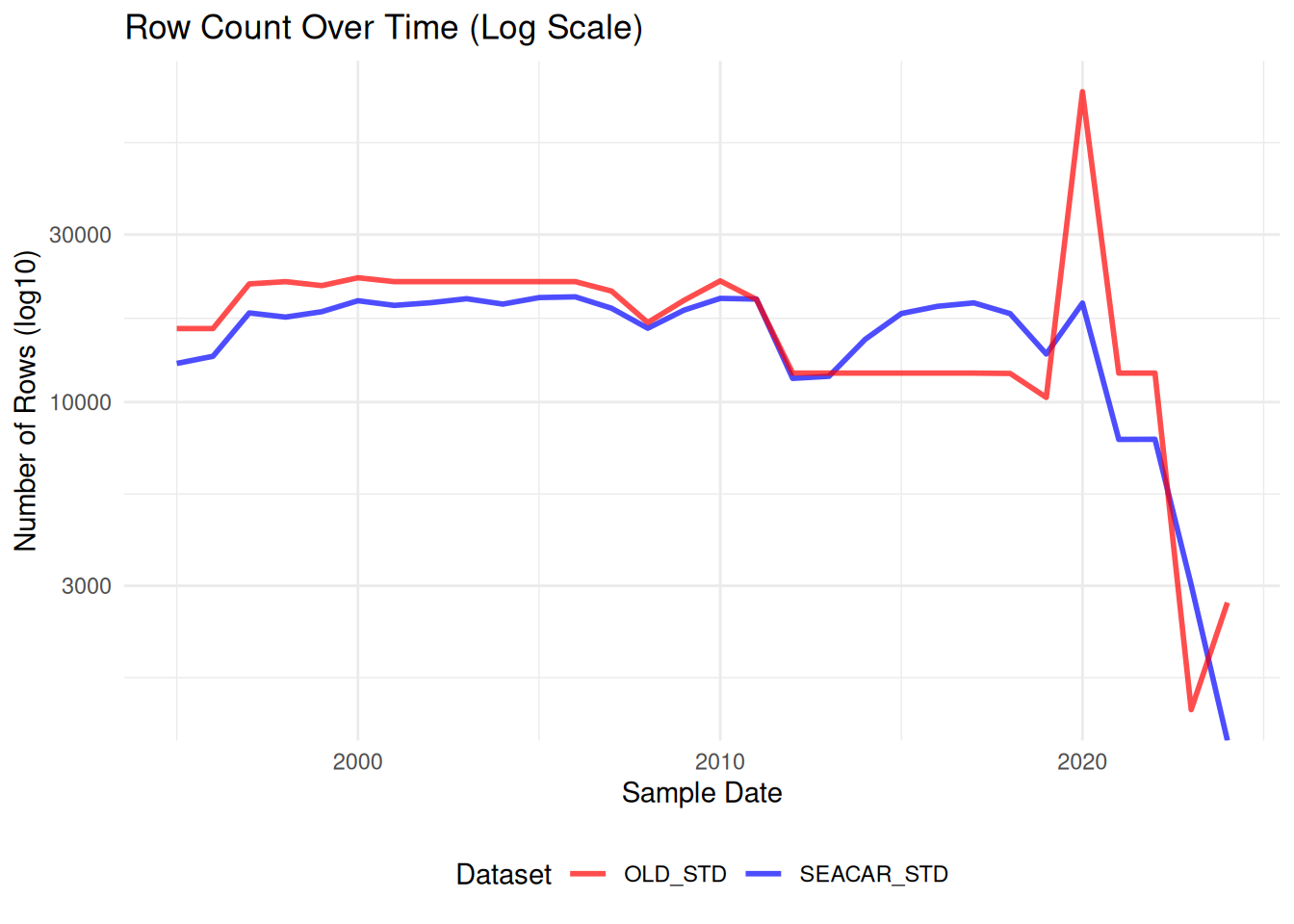
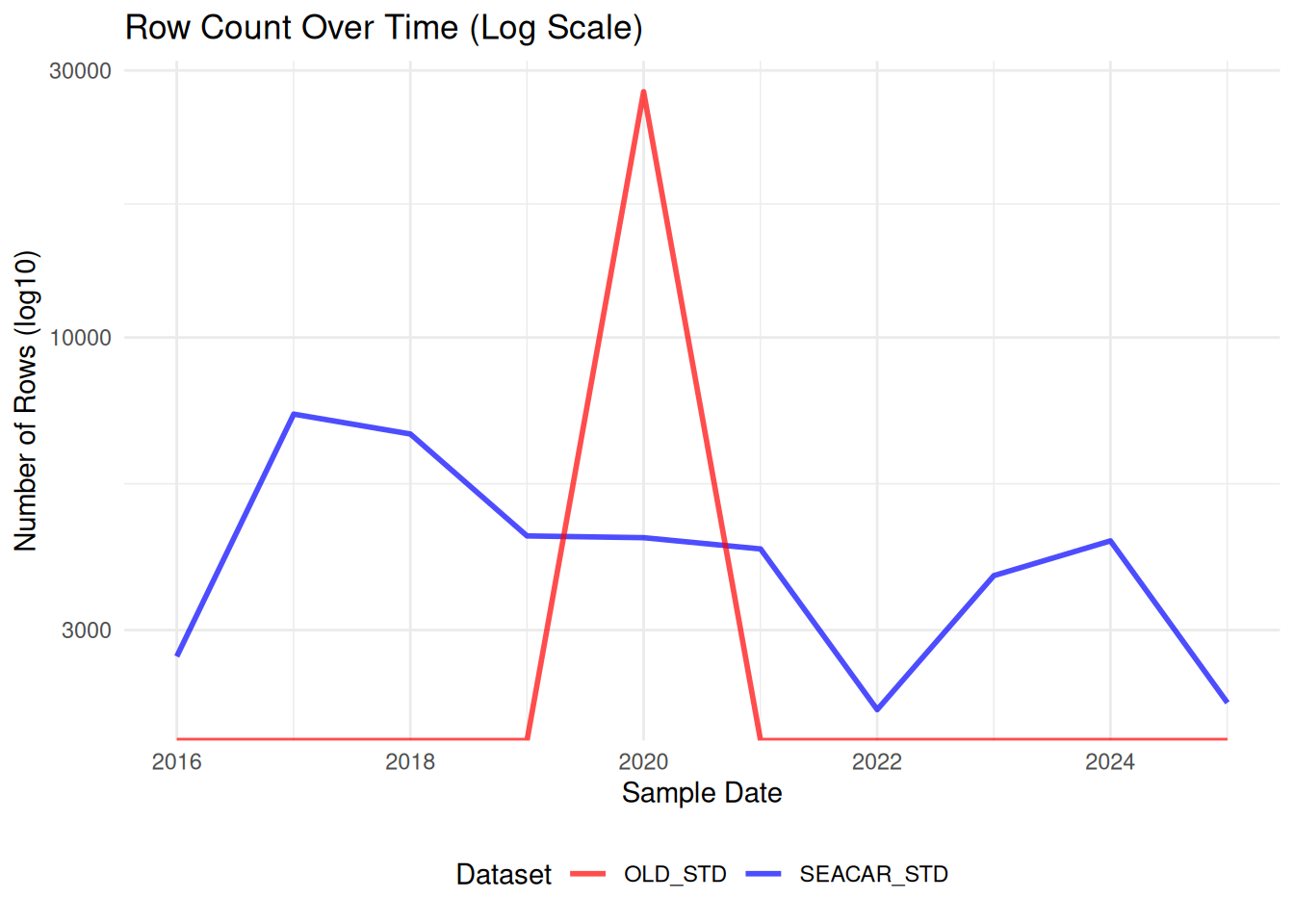
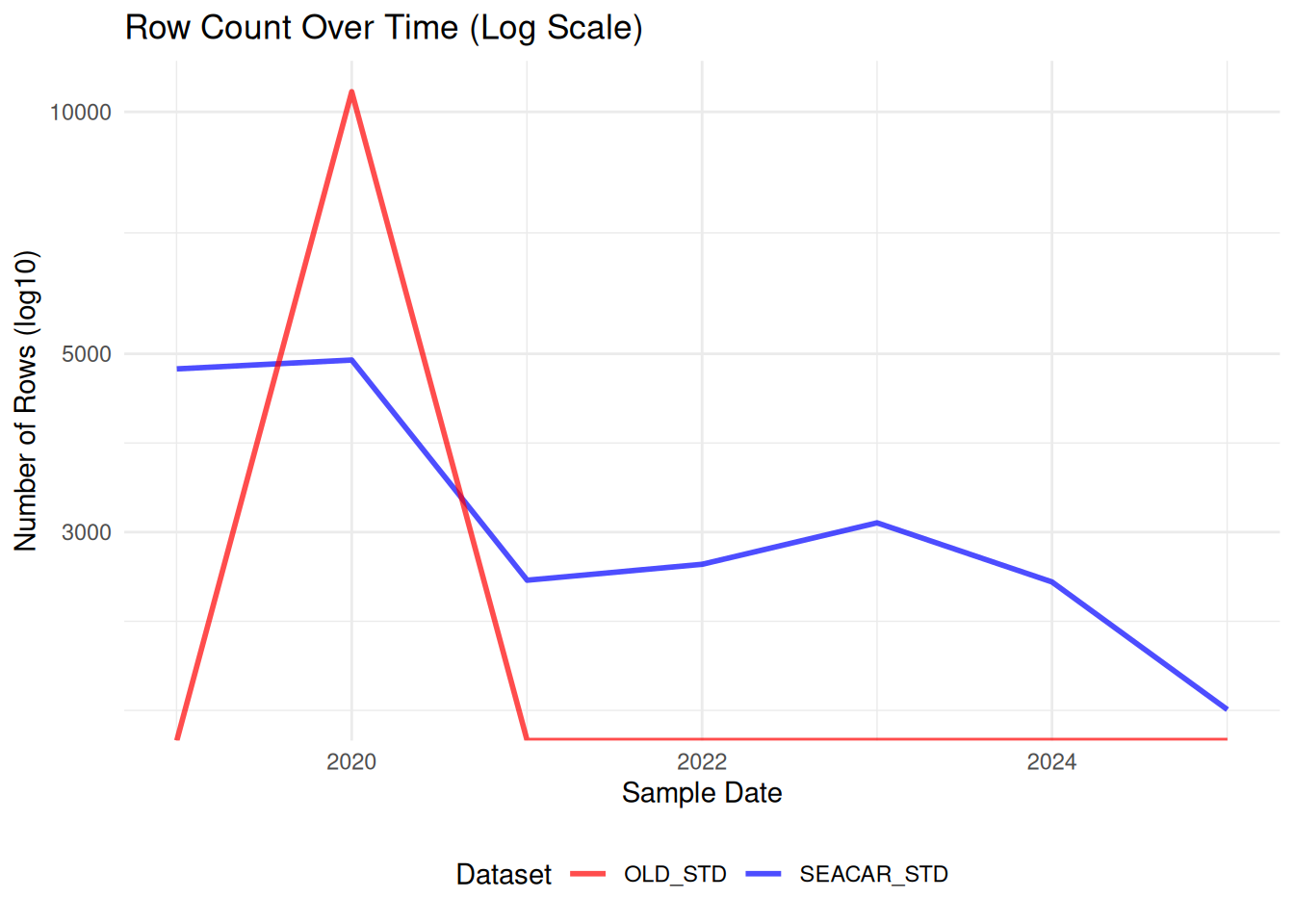
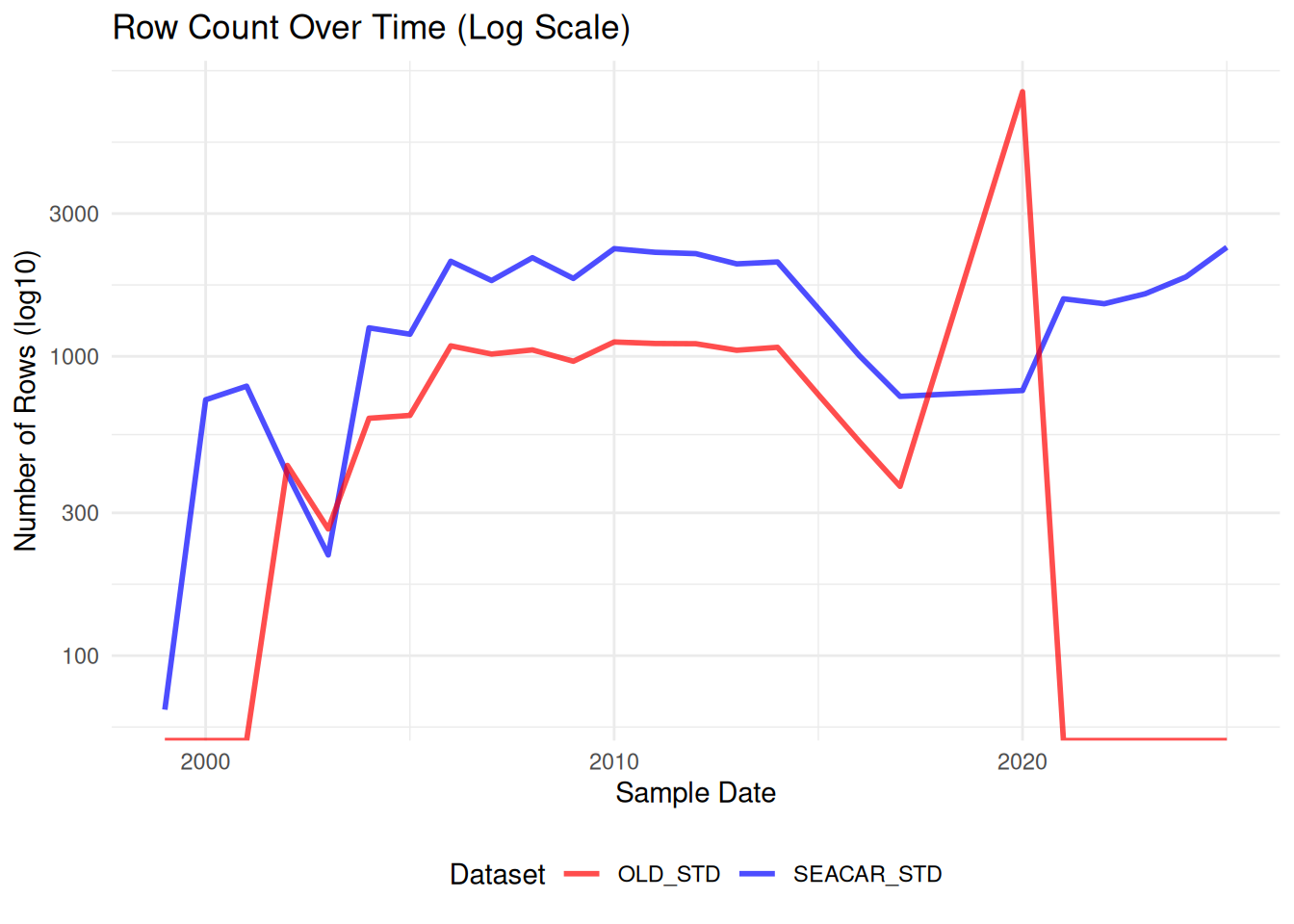
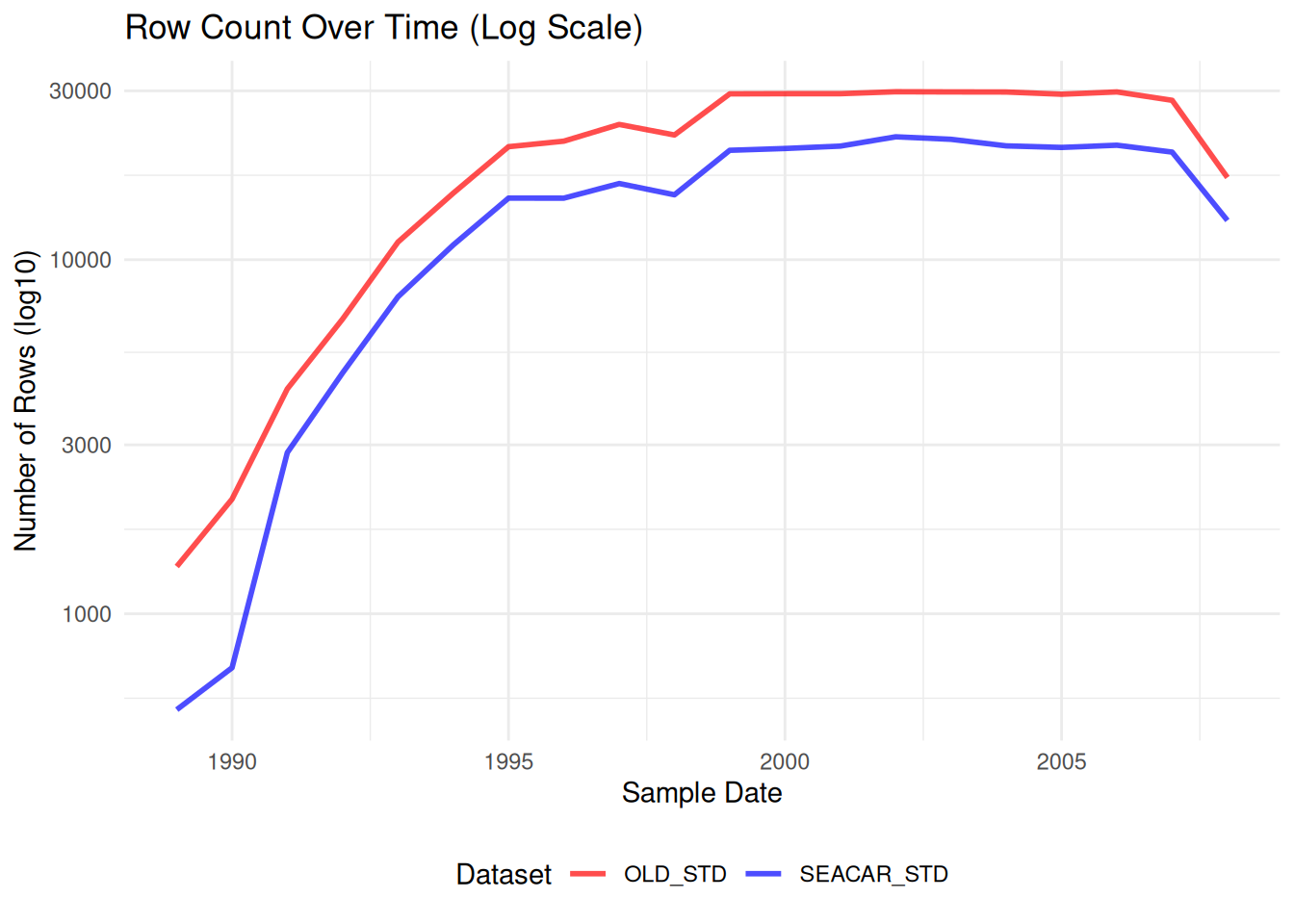
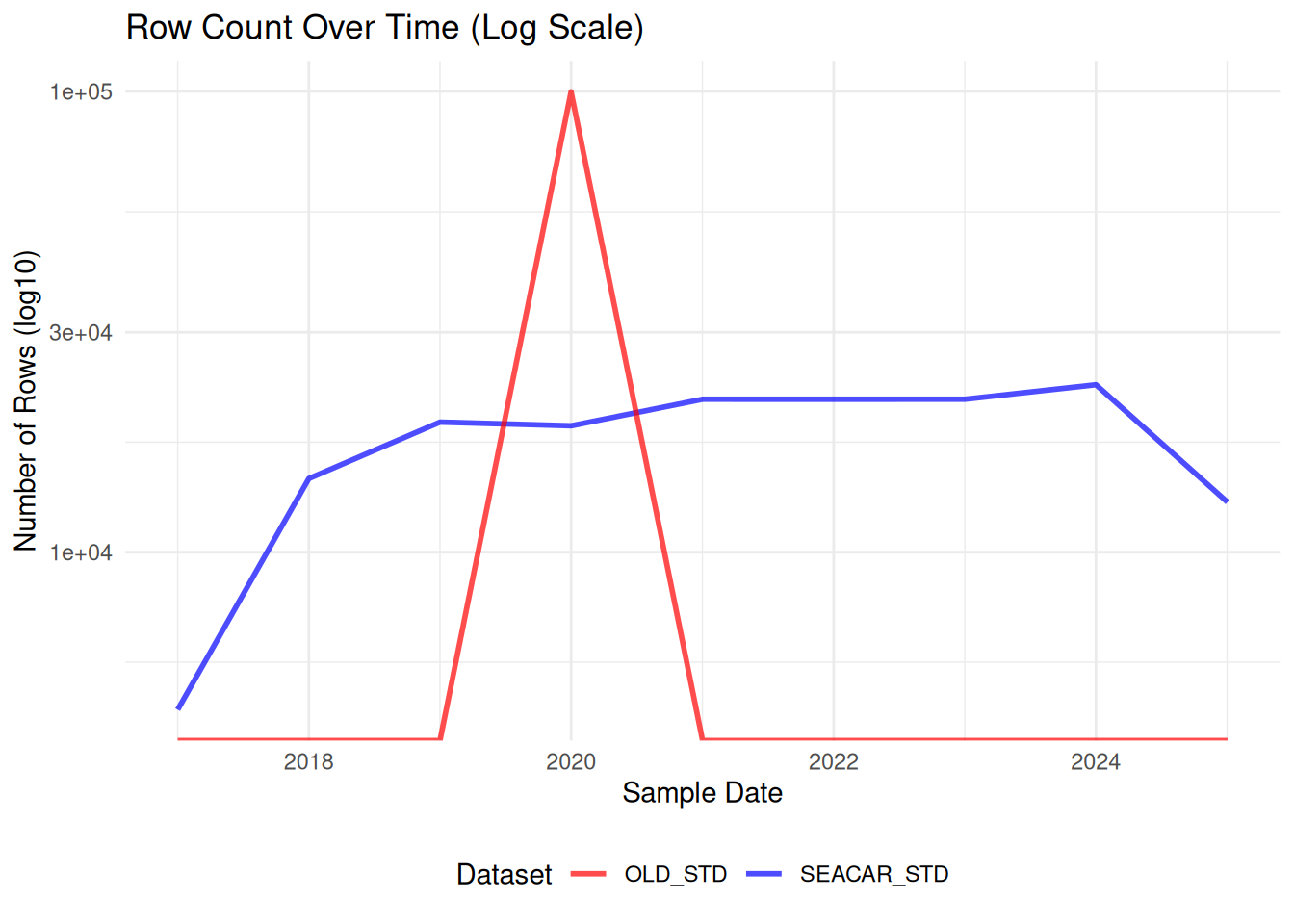
Comparisons between SEACAR and older dataset for each parameter.
Click on any element for more details.
Code
# load each dataset and map ProgramNames to common "shortName" vocabularylibrary(here)library(dplyr)source(here("SEACARProgramCompare/mapProgramNameToShortName.R"))df_SEACAR <- readr::read_delim(here("data/Discrete WQ - 10006.txt"),delim ="|") %>%mutate(ProgramName =mapProgramNameToShortName(ProgramName))df_OLD <- readr::read_delim(here::here("data/allDataSEACAR.csv"), delim=",") %>%mutate(ProgramName =mapProgramNameToShortName(ProgramName))library(dplyr)
compare programs in dataset
# Compares the unique program names between SEACAR and OLD datasets to show overlaps and differences)u1 <-unique(df_SEACAR$ProgramName)u2 <-unique(df_OLD$ProgramName)comparison <-tibble(value =union(u1, u2)) %>%mutate(in_SEACAR = value %in% u1,in_OLD = value %in% u2 )print(comparison, n=100)